
A Heuristic Proof of Practical Aligned Superintelligence
Aligned Superintelligence Can Almost Certainly Be Built

Follow-up to: A Nonconstructive Existence Proof of Aligned Superintelligence
In my previous post I showed that given a reasonable definition of alignment it cannot be the case that aligned AI doesn’t exist. The argument is really quite simple: if you can define it (and your definition isn’t impossible in-principle even by the best possible team of humans) then there must exist some boolean circuit/finite state machine that implements it.
A number of objections were made to that post but they all stemmed from people who either didn’t understand it or were quibbling with the definition of “intelligence” or thought that a non-practical existence proof is not worth anything.
First we’ll review the following: a nonconstructive proof is still a proof.
For example the proof that there exists a rational number (fraction) q, which is equal to an irrational power of an irrational number. What is q? Which specific fraction? We don’t know. But we know that q exists. It’s easy to prove:
Let:
Then:
So let’s say that a as defined above is rational. Then we can say that our fraction q, is simply equal to a. Which specific fraction is it? What is the numerator? What is the denominator? I don’t know. But, by assumption it is equal to some fraction! OK. Now let’s suppose that a is not rational. Then a to the power b, which is equal to 2, is rational (2 is a fraction in the technical sense, it is 2÷1, as are all whole numbers). And we know that b (which is just the square root of two!) is irrational. So in that case our rational number q that is an irrational power of an irrational number is just 2.
The above is a valid proof. That’s how existence proofs work: you do the work to show that something exists, but you do not necessarily have to be certain about which thing it is.
An Aligned World Optimizing Machine - LT:BGRO()
Now let us somewhat extend the results from the previous post. Recall that we defined LT:BGROW to be a lookup table which maps finitely long sensor input sequences to finitely long motor output sequences, such that the resulting state of the world is the best (according to some utility function U) generically realizable state - i.e. the best possible world state which can be realized under generic conditions (i.e. small but finite perturbations don’t change the result) by the actions of a group of humans acting on the world.
We can make the dependence on U explicit, by calling it LT:BGROW(U).
Then, we can consider the set of all utility functions on the universe which are of finite information content less than or equal to the information content of a human mind or even a group of human minds, books, etc: i.e. less than or equal to say 10^15 bits. Call the set of all “humanly describable” utility functions Ψ. Then for any U in the set Ψ, we can define LT:BGROW(U) as before.
Now we can consider the mapping U → LT:BGROW(U) for all U in Ψ. Since Ψ is a finite set and LT:BGROW(U) is just a finitely large object, the mapping itself can simply be recorded as another finitely large lookup table. Call it LT:BGRO(), dropping the W for brevity.
LT:BGRO() = U → LT:BGROW(U)
LT:BGRO() is a computer program which, when fed any “humanly describable” utility function U, optimizes the world to maximize that utility function at least as well as any reasonably sized group of humans possibly could even under the best possible circumstances.
I now claim that LT:BGRO() is a superintelligence according to Bostrom’s definition:
Nick Bostrom defines superintelligence as "any intellect that greatly exceeds the cognitive performance of humans in virtually all domains of interest"
LT:BGRO() must equal the performance of any group of up to, say, 10 billion humans, where each human is the most capable possible human on Earth today in some domain, under the best possible circumstances (as long as those are generic circumstances, i.e. stable under very small perturbations) using all the available resources in the known universe to achieve any outcome that can be described in 10^15 bits or less. So, pretty much by definition LT:BGRO() fits Bostrom’s definition. It is vastly more powerful than any currently existing human or human group at any task you can possibly imagine.
LT:BGRO() is also aligned, by definition. You feed it a utility function U in Ψ and it optimizes the world for U and produces the best generically realizable world according to U.
Practical Aligned World Optimization Must Exist
LT:BGROW and LT:BGRO() are well-defined aligned world optimizers, but their construction is clunky and it is fairly clear that they only exist as mathematical objects, being far too large to actually implement. They are very wasteful of space and compute, because they are constructed to achieve a logical-mathematical goal of being easily definable and obviously real. They are also disembodied (have no physical footprint) to avoid any circularity problems.
But can we also prove that a practical variant of LT:BGRO() exists? I think we can, but we must introduce an additional empirical assumption.
Modern AI has repeatedly shown that for any computational task, if a human can do it then an ML system can also do it and with similar accuracy and similar power consumption, waste heat generation and mass and volume of compute. I.e. Neural Network ML models are comparable functional approximations of all human information processing tasks. Call this the “Efficient Functional Approximation Assumption” (EFAA).
Efficient Functional Approximation Assumption: any information processing task performed by a single human can be performed by some machine operating within known physical laws with equal or lower resources and equal or higher accuracy
10 years ago, many people would have doubted the Efficient Functional Approximation Assumption. LLMs and image AIs have completely crushed that doubt, and I think there’s basically nobody out there who doubts it save perhaps a few quantum woo holdouts or extremely low information people who don’t realize that modern AI is a thing.
Given EFAA we can fairly trivially extend to what I call the Societal Efficient Functional Approximation Assumption (SEFAA).
Societal Efficient Functional Approximation Assumption: any information processing task performed by a whole human society can be performed by some machine operating within known physical laws with equal or lower resources and equal or higher accuracy
SEFAA follows from EFAA and the observation that when we combine many humans together into a society, we typically do so with simple computable functions for the purposes of decision-making. Occasionally we use more complex decision-making functions such as, say, quant finance models. But it’s mostly things like spreadsheets. It’s all computable, and in fact most of it happens on computers nowadays! In creating the machine approximation for SEFAA we replace the machine approximations to humans from EFAA and discard everything that isn’t a decision-making algo, which can only reduce resource use.
Given EFAA and SEFAA we can create an efficient and embodied variant of LT:BGROW. Instead of simply listing the full table of what input/output sequence mapping the best possible human team would use to create the best generically realizable outcome, we make a machine like a Neural Network which efficiently encodes that input/output sequence mapping. Given SEFAA, there must exist a machine approximation to LT:BGROW which achieves a better or equal outcome with less or equal resources than a large team of humans - limited to say 10 billion people, which is about 100GW of electrical power for their brains, assuming 10W per brain of power - that being the actual power use of your brain. 100GW = 876 TWhr/year is slightly less than the electrical consumption of Japan, and about twice that of Germany. The minimal electrical power overhead for the most efficient possible implementations of societal decision-making tools such as spreadsheets, calculators, email, social media websites and voting machines and so on is small in practice so we can just roll it into the 100GW.
Thus we can confidently say that an efficient functional approximation to LT:BGROW exists. It occupies a volume of less than or equal to 13 million cubic meters (0.013 cubic kilometers), has a mass of less than or equal to 13 million tons, it uses less than or equal to 100GW of power (and produces less than or equal to 100GW of waste heat). Furthermore, waste heat and electrically shielded computation in a strong faraday cage defeats any concerns about circularity: the infrastructure of this computation can look completely generic from the outside so its calculations don’t have to depend on themselves in a circular way.
We’ll call the efficient functional approximation to LT:BGROW, FA:BGROW.
RLHF and Vladimir Putin Alignment
I will also now claim that an efficient functional approximation LT:BGRO() must exist, as long as the complexity of the utility function being described is finite and reasonably small. I said 10^15 bits elsewhere, but for practical purposes we seem to not need that much as human preferences probably fit into about 10^10 bits.
Sure, you can make one efficiently computable aligned AI model. But can you define an efficient computable function that “aligns” an AI model to an arbitrary preference set as a parameter? This is not quite the same thing as FA:BGROW in the previous section, which just relies upon there being some arrangement of humans that can get stuff done (which we can then approximate with AI): the arrangements might look very different for different types of goal. Can we do better and have basically ONE arrangement of human or AI agents that will pursue any goal you feed into them?
And it turns out you can! RLHF and PPO have efficiently solved this problem at the individual model level. Indeed, the cost of the pretraining for LLMs is about 98% of the total cost, so the RLHF part is less than 2%* of the training cost (probably more like 0.1% actually, since of that 2% most is the supervised finetuning). It is unclear how much cost RLHF adds to inference for a given level of performance, but over time I suspect that this will fall to similar levels as what is used in training.
Finally there is still the question of how to coordinate many aligned functional approximations to humans into a large-scale entity that achieves arbitrary real-world goals. I posit that we can simply use existing bureaucratic mechanisms that humans use, albeit with some optimizations allowed by AI. This is the so-called “Vladimir Putin Alignment” thesis of Buck Schlergis (Vladimir Putin can control Russia using lots of clever governance mechanisms, so we can control AI the same way).
Indeed, RLHF may obviate the need for most of the Vladimir Putin Alignment tricks (Vlad can’t RLHF his own population - he can’t systematically rewire their brains with the power we can to AIs). So actually it is overdetermined. There are likely many different feasible combinations of RLHF and other RL tricks, and Vladimir Putin Alignment governance mechanisms that work.

We still feel like this is the weakest part of the heuristic proof, but consider what it would mean for this to be wrong. It would mean that functional human societies that optimize for a clear goal just never happen. But that’s empirically wrong! They absolutely do happen. Therefore there must be feasible combinations of individual mental alignment regimes (RLHF, PPO) and collective governance, coordination and control mechanisms (ordinary markets, prediction markets, bureaucracies, rule of law, secret police, spy agencies, meta-spy-agencies etc) that result in specific social behavior. According to Google, a typical military employs about 1-2% of its manpower as military police. In 20th century conflicts where "barrier squads" were used (i.e. troops who would shoot friendly troops who retreated), only a small amount of manpower was needed for them, less than 1%. According to Statista there are 700k law enforcement officers in the USA**, which is about 0.2% of the population. Consistently the resource overhead of governance mechanisms in highly functional Western and Eurasian societies (like those that are at war and winning) is of the order of 1%.
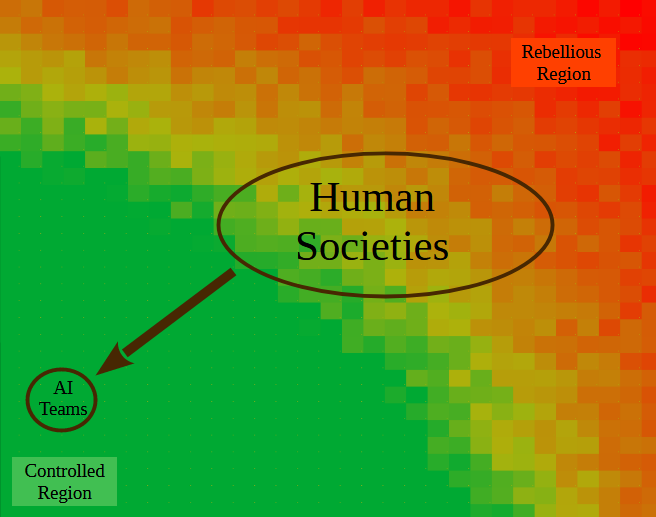
Since at least some human societies have been highly controlled and AI models and societal control mechanisms can both be better, the authors of this post feel that optimally and parametrically aligned AI falls deep within the “controlled region” of the diagram above.
We’ll call the efficient functional approximation to LT:BGRO() , FA:BGRO(). FA:BGRO() means an efficient functional approximation to a rule that converts preferences into realizably optimal action-sequences for a large team of AI agents and robots that maximize those preferences. By “realizably optimal” we mean things that the best possible team of humans could achieve under the best possible circumstances with the best possible systems of coordination and governance.
FA:BGRO() is still nonconstructive. It doesn’t tell you which RLHF dataset to use or what specific governance or coordination mechanisms to use. But it says that whatever the best possible answers for making a utopia in the pre-AI age are, you can almost certainly practically implement those same answers (or better) with AI.
AI Alignment is Not Just Possible, it’s Easy
Computers can add numbers much more accurately than humans. They can draw better pictures than humans. They can play better chess. See the pattern?
Well, AIs will soon be able to generate desired outcomes for society better than humans can. They will be able to do it much more easily and safely and reliably than humans. We will look back on the age of human governance of human society as a dark age. The idea of technical barriers to AI alignment will seem silly, like the idea of technical barriers to building a calculator that can do cube roots.
I feel that the AI Alignment discourse has become somewhat detached from both reality (RLHF for human values was easy compared to making human-level-capability AI at all, actually) and from sane theory (basic empirical facts and math that’s nearly a century old make AI Alignment provably possible).
This post is an attempt to correct that state of affairs.
⬜
* “Pretraining is the most resource-intensive phase. For the InstructGPT model, pretraining takes up 98% of the overall compute and data resources” — from https://huyenchip.com/2023/05/02/rlhf.html
** https://www.statista.com/statistics/191694/number-of-law-enforcement-officers-in-the-us/
The basic problem with this (that I can see) is that you begin with a highly abstract proof of the existence of an AIXI-style mathematical formalism (representing an idealised superintelligence), and then shift to empirical, heuristic arguments based on extrapolations from current technology and social systems. These are quite different kinds of argument, and the former does not necessarily shed much insight on the latter.
On your AIXI-style proof: as far as I can tell the core idea is that the universe is finite, and that therefore any kind of intelligent agent within the universe could in principle be replaced with a ginormous lookup table. (Presumably this includes agents that receive some inputs S1...St, take some action At, receive new inputs St+1...St+n, take another action, etc.) [1]
I do not think anyone familiar with mathematics and computer science would argue with this. The problem is it does not shed much light on the empirical, heuristic arguments you make in this article. I think there are practical or philosophical criticisms that could be made of the empirical arguments you make above, but by framing the argument in terms of mathematics you preempt most such criticisms, as you can simply say the critics don't understand or haven't addressed the mathematical arguments you make.
[1] Regarding modelling an intelligent agent as a lookup table, there is a tangential problem, which is separate from my points above, but which I think is relevant. Take any intelligence agent -- superintelligent or not -- which updates on new information. To model such an agent -- one that begins not knowing everything -- the lookup table or equivalent basically has to incorporate all information in the universe, or at least all information the agent would act on once it possesses it.
E.g., suppose you are modelling a strictly limited tool AI that performs chemistry experiments, and uses the results of those experiments to plan new experiments. Assume the AI's decisions are determined by the data it has received up to a given point, s.t. it can be modelled by a lookup table or equivalent structure such as you describe. The lookup table therefore *has to incorporate* (in some form) a model of all of the aspects of chemistry the AI might conceivably interact with. If the AI is able to synthesise new molecules, the model has to be even more complicated.
For a superintelligent agent, the same argument would hold, but the lookup table in essence has to incorporate a model of the entire universe -- including the complete laws of physics and the physical properties of every entity that the SAI might interact with. By "incorporate a model" I mean that the astronomically vast network of inputs and outputs constituting the lookup table would in some sense have to correspond to a complete model of the universe (amongst other things).
Discuss this on LessWrong:
https://www.lesswrong.com/posts/qcdTQQLeaGzFQKXed/a-heuristic-proof-of-practical-aligned-superintelligence
Discuss this on Reddit:
https://www.reddit.com/r/slatestarcodex/comments/1g1bjdh/a_heuristic_proof_of_practical_aligned/